-1.png?height=120&name=SAPP%20logo%20m%E1%BB%9Bi-01%20(1)-1.png)
Dữ liệu lớn là thuật ngữ dùng để chỉ một tập hợp dữ liệu rất lớn mà những công cụ, kỹ thuật phân tích dữ liệu truyền thống không thể xử lý. Trí tuệ doanh nghiệp hỗ trợ đưa ra quyết định và tối ưu hóa hiệu suất hoạt động...
I. Mục tiêu
- Xác định dữ liệu lớn (big data) và giải thích mô hình 4V (volume, velocity, variety, veracity).
- Tìm hiểu cách doanh nghiệp sử dụng dữ liệu có cấu trúc (structured data), bán cấu trúc (semi-structured data), và phi cấu trúc (unstructured data).
- Tìm hiểu về tiến trình của dữ liệu.
- Xác định cơ hội và thách thức của việc quản lý phân tích dữ liệu.
- Xác định trí tuệ doanh nghiệp (business intelligence).
II. Nội dung
Dữ liệu lớn tập hợp các bộ dữ liệu rất lớn và/ hoặc phức tạp giúp cải thiện việc ra quyết định và chiến lược doanh nghiệp.
Trí tuệ doanh nghiệp (BI) và phân tích dữ liệu (data analytics) hỗ trợ doanh nghiệp chuyển đổi dữ liệu từ dữ liệu thô thành chiến lược hành động.
Dữ liệu lớn và phân tích dữ liệu có thể trở thành tài sản chiến lược quan trọng đối với doanh nghiệp.
1. Dữ liệu lớn (big data)
Dữ liệu lớn là thuật ngữ dùng để chỉ một tập hợp dữ liệu rất lớn và/hoặc phức tạp mà những công cụ, kỹ thuật phân tích dữ liệu truyền thống không thể xử lý.
Dữ liệu lớn được sử dụng để hiểu rõ hơn về các mối quan hệ và đoàn thể (associations) nhằm cải thiện việc ra quyết định và chiến lược doanh nghiệp.
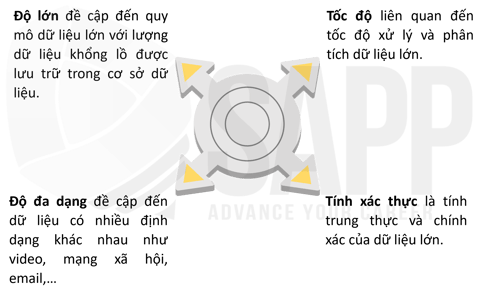
Dữ liệu lớn có thể được nhận dạng thông qua 4 khía cạnh đặc điểm là độ lớn (volume), độ đa dạng (variety), tốc độ (velocity), và tính xác thực (veracity).
2. Cấu trúc dữ liệu
Dữ liệu có thể được cấu trúc hoặc tổ chức theo nhiều cách khác nhau.
| Dữ liệu có cấu trúc (Structure data) |
Dữ liệu ở dạng chuẩn hóa, thường ở dạng bảng (spreadsheet) bao gồm các hàng và cột xác định rõ các thuộc tính dữ liệu giúp dễ dàng tìm kiếm và truy cập một cách hiệu quả. |
| Dữ liệu bán cấu trúc (Semi-structure data) |
Thiếu mô hình dữ liệu dạng bảng hoặc quan hệ cụ thể, nhưng bao gồm siêu dữ liệu có thể phân tích được như thẻ (tags) hoặc điểm đánh dấu (makers). Ví dụ: email, tệp nén, tệp trên web,… |
| Dữ liệu phi cấu trúc (Unstructure data) |
Thông tin không có mô hình dữ liệu được thiết lập hoặc dữ liệu chưa được sắp xếp theo cách định sẵn. Ví dụ: tệp văn bản, tệp video, hình ảnh,… |
3. Tiến trình của dữ liệu
a. Trí tuệ doanh nghiệp (BI) và tiến trình của dữ liệu
Trí tuệ doanh nghiệp là tập hợp các ứng dụng, công cụ, và phương pháp tối ưu nhất giúp chuyển đổi dữ liệu (dạng thô) thành “trí tuệ” (kiến thức, hiểu biết) có ý nghĩa, hỗ trợ đưa ra quyết định và tối ưu hóa hiệu suất hoạt động.
Bản thân dữ liệu có ý nghĩa rất hạn chế và không có tổ chức nên cần được xử lý thông qua tiến trình sau:

-
- Dữ liệu: là số liệu thống kê, ký hiệu, ký tự, con số hoặc văn bản thiếu cấu trúc và chưa được sắp xếp theo cách định sẵn.
- Thông tin: khi dữ liệu được sắp xếp và có tổ chức sẽ chuyển thành thông tin. Thông tin mang ý nghĩa và sự hiểu biết.
- Kiến thức: được xác định và tạo ra từ thông tin. Kiến thức là những gì chúng ta biết và cách chúng ta hiểu vấn đề.
- Hành động: từ kiến thức, phân tích chuyên sâu được thực hiện thông qua tư duy logic để đưa ra các chiến lược hành động.
b. Phân tích dữ liệu (data analytics)
Phân tích dữ liệu xử lý dữ liệu thành thông tin bằng cách tổ chức dữ liệu và sử dụng các kỹ thuật phân tích để hiểu rõ hơn về các mối quan hệ, mô hình, xu hướng và nguyên nhân.
Phân tích dữ liệu là một bước quan trọng trong quá trình chuyển dữ liệu thành thông tin, là tài sản chiến lược đồng thời cũng tồn tại một số thách thức đối với doanh nghiệp.

III. Bài tập
Question 1:
Big data earned its name, because it is different from previous methods of data analysis in four main ways: the "Four Vs" of big data. One way that big data is different is the rapid production and processing of information. Which of the "Four Vs" of big data is most applicable to this definition?
A. Variety
B. Volume
C. Velocity
D. Veracity
Answer:
→ The answer is choice C
C is correct. The "Four Vs" of big data are velocity (the speed at which data is gathered and processed); volume (the amount of storage required to retain the data gathered); variety (the spread of data types across sensor values, numbers, text, pictures, etc.); and veracity (the accuracy of the data and the presumption that data within the same dataset may be of different quality). Velocity means speed, and often, big data applications create data very rapidly. Some applications require that decisions be made quickly. This is seen in self-driving cars, which have many sensors creating data that a computer uses to determine road conditions and to react quickly with driving decisions.
A is incorrect. Valiant is having or showing heroism or courage. This is not one of the "Four Vs" of big data.
B is incorrect. Volume is the size of the data. This question is most focused on the speed of incoming data and the speed of making decisions based on that data, the velocity.
D is incorrect. Veracity is the accuracy of the data, and the expectation that when a company gathers big data, some of that data will likely be of different quality. Any processing that is done on the big data must be able to handle varying degrees of data quality.
Question 2:
What type of data file contains a strong pattern of identified components, listed in a consistent order within each record, and clearly separated by a delimiter or a fixed size?
A. Unstructured
B. Semi-structured
C. Structured
D. Infra-structured.
Answer:
→ The answer is choice C
C is correct. Unstructured data is data with no underlying pattern, such as text messages. Structured data is highly ordered with a strong underlying pattern of identified components in a consistent order within each record and a clear separator. Semi-structured data is in between, such as text messages with a string of hashtags or other metadata intended to link similar articles together, or numbers with labels where those numbers can only be processed after the labels are interpreted. The question describes a file with a strong underlying pattern among its components: the definition of structured data.
A is incorrect. Unstructured data has no underlying pattern, such as text messages, where the ideas in the messages are the desired data. The ideas may be present, but because they are encoded in language, it is not easy for a program to locate and evaluate them correctly.
B is incorrect. Semi-structured data has a weak underlying pattern, one made from metadata tags or highly various labels.
D is incorrect. Infra-structured data is not a type of data structure.