-1.png?height=120&name=SAPP%20logo%20m%E1%BB%9Bi-01%20(1)-1.png)
- SAPP Knowledge Base
- Tự học CFA Level I (Chartered Financial Analyst)
- [Level 1] Quantitative Methods
-
ACCA Customer Experience
-
Hỗ trợ học viên ACCA & những câu hỏi thường gặp (FAQs)
-
Hỗ trợ học viên CFA & câu hỏi thường gặp (FAQs)
-
Hỗ trợ học viên CMA và các câu hỏi thường gặp (FAQs)
-
Tự học ACCA (Association of Chartered Certified Accountant)
- Các thủ tục liên quan đến ACCA
- Tổng quan về ACCA
- Kinh nghiệm tự học và thi các môn ACCA
- [BT/F1] Business and Technology (Kinh doanh và Công nghệ)
- [MA/F2] Management Accounting (Kế toán Quản trị)
- [FA/F3] Financial Accounting (Kế toán Tài chính)
- [LW/F4] Law INT (Luật Quốc tế)
- [PM/F5] Performance Management - Quản lý Hiệu quả hoạt động
- [TX/F6] Taxation - Thuế Việt Nam
- [FR/F7] Financial Reporting (Lập báo cáo Tài chính)
- [AA/F8] Audit and Assurance (Kiểm toán và Các dịch vụ đảm bảo)
- [FM/F9] Financial Management (Quản trị Tài chính)
- [SBR/P2] Strategic Business Reporting (Báo cáo chiến lược kinh doanh)
- Kinh nghiệm học thi ACCA
-
Từ điển Chuyên ngành ACCA
- [ACCA BT/F1] – Từ điển môn Business and Technology
- [ACCA MA/F2] - Từ điển môn Management Accounting
- [ACCA FA/F3] - Từ điển môn Financial Accounting
- [ACCA LW/F4] - Từ điển môn Corporate and Business Law
- [ACCA PM/F5] - Từ điển môn Performance Management
- [ACCA TX/F6] - Từ điển môn Taxation
- [ACCA AA/F8] - Từ điển môn Audit and Assurance
- [ACCA FM/F9] - Từ điển môn Financial Management
-
Tự học FIA (Foundation in Accountancy)
-
Tự học CFA Level I (Chartered Financial Analyst)
- Tổng quan về CFA
- Kinh nghiệm tự học và ôn thi CFA Level I
- [Level 1] Quantitative Methods
- [Level 1] Economics
- [Level 1] Financial Statement Analysis
- [Level 1] Corporate Issuers
- [Level 1] Equity Investments
- [Level 1] Fixed Income Investments
- [Level 1] Derivatives
- [Level 1] Alternative Investments
- [Level 1] Portfolio Management
- [Level 1] Ethical & Professional Standards
- Tài liệu Pre CFA level 1
- Các thủ tục liên quan đến CFA
- Chính sách học viên CFA
-
Tự học CFA Level II (Chartered Financial Analyst)
- [Level II] Quantitative Methods
- [Level II] Economics
- [Level II] Financial Reporting and Analysis
- [Level II] Corporate Issuers
- [Level II] Equity Valuation
- [Level II] Fixed Income
- [Level II] Derivatives
- [Level II] Alternative Investments
- [Level II] Portfolio Management
- [Level II] Ethical and Professional Standards
-
Tự học CFA Level III (Chartered Financial Analyst)
-
Tự học CFA Institute Investment Foundations
-
Từ điển chuyên ngành CFA
-
Tự học CMA Part 1 (Certified Management Accountant)
-
Tự học CMA Part 2 (Certified Management Accountant)
-
Kinh nghiệm thi tuyển Big4 và Non Big
- Kinh nghiệm tuyển dụng các công ty Non- Big
- Big 4 - Các tiêu chí tuyển dụng
- Big 4 - Kinh nghiệm cho Vòng CV
- Big 4 - Kinh nghiệm cho vòng test năng lực phần kiến thức chuyên môn
- Big 4 - Kinh nghiệm cho vòng test năng lực phần Verbal reasoning
- Big 4 - Kinh nghiệm cho vòng test năng lực phần Numerical reasoning
- Big 4 - Kinh nghiệm cho vòng test năng lực phần Essay
- Big 4 - Kinh nghiệm cho vòng phỏng vấn nhóm
- Big 4 - Kinh nghiệm cho vòng phỏng vấn cá nhân
- Chia sẻ kinh nghiệm làm việc tại Big4
-
Nghề nghiệp và kinh nghiệm thi tuyển trong lĩnh vực Kế Kiểm Thuế
-
Nghề nghiệp và kinh nghiệm thi tuyển trong lĩnh vực Tài Chính
-
Kinh Nghiệm Học & Thi Chứng Chỉ Kế Toán Quản Trị Hoa Kỳ CMA
[Tóm tắt kiến thức quan trọng] Module 6: Simulation Methods
Bài viết cung cấp cho người đọc kiến thức về Module 6 môn Quantitative Methods của chương trình CFA level I
[LOS 6.a] Giải thích mối quan hệ giữa phân phối chuẩn và phân phối loga chuẩn; trình bày lý do phân phối loga chuẩn được sử dụng để lập mô hình định giá tài sản
Phân phối loga chuẩn được tạo ra bởi hàm,![]() . Trong đó, x được phân phối chuẩn. Phân phối loga chuẩn có các đặc tính chính như sau:
. Trong đó, x được phân phối chuẩn. Phân phối loga chuẩn có các đặc tính chính như sau:
-
Phân phối loga chuẩn bị lệch sang phải, do giới hạn dưới luôn là 0.
-
Phân phối loga chuẩn không bao giờ âm.
Công thức của continuous compounding
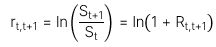
[Pre.i] Mô tả các tính chất của phân phối Student's T; tính toán và giải thích các bậc tự do của nó
Phân phối T: Phân phối T là phân phối xác suất đối xứng được xác định bởi một tham số duy nhất được gọi là bậc tự do (degree of freedom).
Phân phối T so với phân phối chuẩn:
-
Phân phối T có đuôi béo hơn so với phân phối chuẩn.
-
Bậc tự do (degree of freedom): df = n-1 (n là cỡ mẫu).
-
Khi df tăng, hình dạng của phân phối t tiến tới phân phối chuẩn.
[Pre.ii] Mô tả các tính chất của phân phối Chi-square và phân phối F; tính toán và giải thích các bậc tự do của chúng
Phân phối Chi-square: Phân phối Chi-square là tổng bình phương của k biến ngẫu nhiên chuẩn độc lập có phân phối chuẩn. Phân phối Chi-square có các đặc tính chính sau:
-
Hình dạng của nó là không đối xứng.
-
Nó không nhận các giá trị âm.
Phân phối F: Phân phối F là phân phối không đối xứng được giới hạn từ bên dưới bởi 0 và liên quan trực tiếp đến phân phối Chi-square.
-
Phân phối F có 2 bậc tự do.
-
Khi bậc tự do của cả tử số (df1) và mẫu số (df2) đều tăng, hàm mật độ cũng sẽ trở thành đường cong giống hình chuông hơn.
[LOS 6.c] Mô tả các phương pháp tái chọn mẫu để ước tính phân phối lấy mẫu của một thống kê
Tái chọn mẫu (resampling) là một công cụ tính toán lặp lại các mẫu từ mẫu dữ liệu quan sát ban đầu để suy luận thống kê các tham số dân số.
Các phương pháp lấy mẫu phổ biến:
-
Bootstrap: Lấy mẫu bằng cách lặp đi lặp lại từ mẫu ban đầu để tìm sai số chuẩn và khoảng tin cậy.
-
Jackknife: Lấy mẫu dữ liệu quan sát ban đầu và loại bỏ một quan sát tại một thời điểm từ tập hợp (và không thay thế nó).