-1.png?height=120&name=SAPP%20logo%20m%E1%BB%9Bi-01%20(1)-1.png)
Bài viết cung cấp cho người đọc kiến thức về Module 11 môn Quantitative Methods của chương trình CFA level I
[LOS 11.a] Định nghĩa “Fintech”
Thuật ngữ "fintech" thường đề cập đến sự đổi mới dựa trên công nghệ của ngành dịch vụ tài chính. Trong bài đọc này, fintech đề cập đến sự đổi mới công nghệ trong việc thiết kế và cung cấp các dịch vụ và sản phẩm tài chính.
Các lĩnh vực phát triển của fintech:
-
Phân tích bộ dữ liệu lớn: Tăng chức năng để xử lý lượng lớn dữ liệu có thể đến từ nhiều nguồn và tồn tại dưới nhiều hình thức khác nhau.
-
Công cụ phân tích: Các công cụ và kỹ thuật như trí tuệ nhân tạo để phân tích các tập dữ liệu rất lớn hoặc phi tuyến tính.
-
Giao dịch tự động và tư vấn tự động: Tự động hóa các chức năng tài chính như thực hiện giao dịch và cung cấp tư vấn đầu tư.
-
Lưu trữ hồ sơ tài chính: Các công nghệ mới được tạo ra nhằm mục đích lưu giữ hồ sơ tài chính để tối giản hóa các công cụ trung gian (chẳng hạn như công nghệ sổ cái phân tán).
[LOS 11.b] Mô tả Big Data, trí tuệ nhân tạo và machine learning
1. Big Data
Big Data hướng đến tất cả các thông tin hữu ích được tạo ra trong nền kinh tế, bao gồm dữ liệu từ:
Nguồn dữ liệu truyền thống:
-
Thị trường tài chính: Giá và khối lượng giao dịch,…
-
Dữ liệu công ty: Báo cáo hàng năm, hồ sơ quy định, dữ liệu bán hàng và doanh thu,…
-
Dữ liệu thống kê kinh tế của chính phủ.
Nguồn dữ liệu phi truyền thống:
-
Cá nhân: Bài đăng trên mạng xã hội, online reviews, email và lượt truy cập trang web,…
-
Công ty: Hồ sơ ngân hàng, thông tin về nhà cung cấp,..
-
Internet vạn vật: Mạng lưới các thiết bị sử dụng cảm biến, các thiết bị thông minh sử dụng chip.
1.1. Đặc điểm của Big Data
-
Khối lượng dữ liệu rất lớn: Hàng triệu, hoặc thậm chí hàng tỷ điểm dữ liệu.
-
Tốc độ truyền dữ liệu nhanh: Dữ liệu thời gian thực (độ trễ thấp) hoặc dữ liệu gần thời gian thực.
-
Sự đa dạng: Dữ liệu được thu thập từ nhiều nguồn khác nhau và ở nhiều hình thức khác nhau (có cấu trúc, dữ liệu bán cấu trúc và phi cấu trúc).
1.2. Phương pháp xử lý dữ liệu
-
B1: Thu thập dữ liệu và chuyển đổi nó thành các hình thức có thể sử dụng được.
-
B2: Đảm bảo chất lượng dữ liệu bằng cách điều chỉnh dữ liệu không đạt yêu cầu.
-
B3: Lưu trữ và truy cập dữ liệu.
-
B4: Kiểm tra dữ liệu được lưu trữ để tìm thông tin cần thiết.
-
B5: Di chuyển dữ liệu từ nơi lưu trữ đến nơi cần thiết.
1.3. Trích xuất thông tin từ Big data
-
Dữ liệu có cấu trúc: Được trực quan hóa bằng cách dùng bảng, biểu đồ và xu hướng.
-
Dữ liệu phi cấu trúc: Các kỹ thuật mới của trực quan hóa dữ liệu: Đồ họa ba chiều tương tác (3D) cũng như bản đồ nhiệt, sơ đồ cây và biểu đồ mạng, tag cloud.
1.4. Những thách thức khi sử dụng Big data trong phân tích đầu tư
Việc sử dụng Big data có thể gặp phải một số khó khăn khi nó được sử dụng trong phân tích đầu tư, bao gồm:
-
Chất lượng: Tập dữ liệu được chọn có tác động của hành vi, thiếu dữ liệu hoặc dữ liệu ngoại lai.
-
Khối lượng: Không đủ.
-
Sự phù hợp: Không phù hợp với loại phân tích.
-
Tập dữ liệu với dữ liệu phi cấu trúc có thể cực kỳ khó khăn để được tìm nguồn, làm sạch dữ liệu và quản lý trước khi phân tích.
Vì Big data gặp phải những vấn đề trên, nên Trí tuệ nhân tạo và Machine learning xuất hiện nhằm hỗ trợ công việc trên các nguồn thông tin lớn và phức tạp như vậy.
2. Trí tuệ nhân tạo (Artificial intelligence)
Hệ thống máy tính Trí tuệ nhân tạo: Được lập trình để mô phỏng nhận thức của con người và có khả năng ra quyết định tương đương hoặc vượt trội hơn so với con người.
Mạng nơ-ron (Neural networks): Được lập trình để xử lý thông tin theo cách tương tự như bộ não con người.
Machine learning: Liên quan đến thuật toán máy tính trích xuất kiến thức từ một lượng lớn dữ liệu mà không đưa ra bất kỳ giả định nào về phân phối xác suất cơ bản của dữ liệu.
3. Machine learning
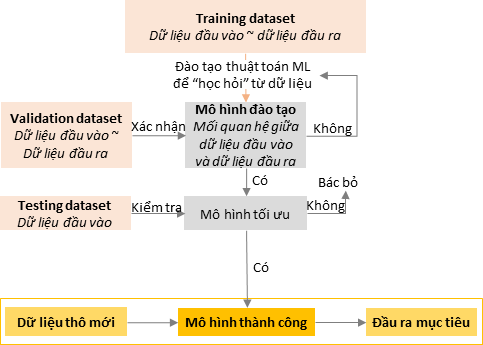
3.1. Cách thức hoạt động của Machine learning bao gồm các giai đoạn sau:
Training dataset là một tập dữ liệu dùng để huấn luyện cho mô hình của thuật toán Machine learning. Đây thường là một tập dữ liệu có kích thước lớn, được dùng để đào tạo trong quá trình huấn luyện Machine learning.
Validation dataset là tập các giá trị đầu vào đi kèm với giá trị đầu ra và được dùng để kiểm tra độ chính xác của mô hình Machine learning trong quá trình huấn luyện.
Testing dataset là tập các dữ liệu đầu vào và được dùng để kiểm tra độ chính xác của những mô hình Machine learning sau khi được huấn luyện.
Khi một thuật toán đã được Training, Validation và Testing, mô hình Machine learning có thể được sử dụng để dự đoán kết quả dựa trên các bộ dữ liệu khác.
3.2. Những thách thức khi sử dụng Machine learning trong xử lý dữ liệu
Dữ liệu quá khớp (Overfitting)
Việc trang bị dữ liệu quá khớp xảy ra khi thuật toán Machine learning học tập Training dataset quá chính xác, coi các biến nhiễu là tham số → Mô hình quá phức tạp để mô tả một tập dữ liệu khác.
→ Xác định các mô hình giả mạo hoặc không có căn cứ.
→ Lỗi dự đoán và dự báo đầu ra không chính xác.
Dữ liệu chưa khớp (Underfitting)
Việc dữ liệu chưa khớp xảy ra khi mô hình Machine learning coi các tham số thực là các biến nhiễu. → Mô hình quá đơn giản và không thể nhận ra các mối quan hệ trong tập dữ liệu đào tạo.
→ Không thể hiện đầy đủ các mô hình làm nền tảng cho dữ liệu.
Hộp đen (Black box)
Hộp đen (Black box) là hiện tưởng xảy ra khi các mô hình Machine learning không giải thích được vì sao mình cho ra được kết quả này.
3.3. Các loại Machine learning
Supervised learning
Máy tính học cách mô hình hóa các mối quan hệ dựa trên dữ liệu được gắn nhãn (labeled data). Sau khi đào tạo cho dữ liệu được gắn nhãn, các thuật toán được sử dụng để lập mô hình hoặc dự đoán kết quả cho các bộ dữ liệu mới.
Unsupervised learning
Máy tính không được cung cấp dữ liệu được gắn nhãn mà thay vào đó chỉ được cung cấp dữ liệu không được gắn nhãn (unlabeled data) và thuật toán phải tự tìm cách mô tả dữ liệu và cấu trúc của chúng.
Deep learning
Máy tính sử dụng mạng nơ-ron, thường có nhiều lớp ẩn, để thực hiện xử lý dữ liệu đa tầng, phi tuyến tính để xác định các mô hình → Có thể sử dụng các phương pháp Machine learning có Supervised hoặc Unsupervised.
[LOS 11.c] Mô tả các ứng dụng fintech trong quản lý đầu tư
|
|
Định nghĩa |
Ứng dụng |
|
Phân tích văn bản |
Phân tích dữ liệu phi cấu trúc dưới dạng văn bản hoặc giọng nói. |
Đánh giá hồ sơ quy định của công ty, báo cáo dưới dạng văn bản, phương tiện truyền thông xã hội, email, bài đăng trên internet, khảo sát,.. |
|
Xử lý ngôn ngữ tự nhiên |
Sử dụng khoa học máy tính, AI và ngôn ngữ học để phát triển các chương trình máy tính nhằm phân tích và giải thích ngôn ngữ của con người. |
|