[LOS 7.a] So sánh và đối chiếu các chọn mẫu xác suất với chọn mẫu phi xác suất
Có 2 phương pháp lấy mẫu, bao gồm:
-
Lấy mẫu xác suất (Probability Sampling)
-
Lấy mẫu phi xác suất (Non-probability Sampling)
1. Lấy mẫu xác suất (Probability Sampling)
-
Simple Random Sampling: Mẫu được chọn ngẫu nhiên và các quan sát trong tổng thể đều có xác suất được lấy vào mẫu như nhau.
-
Systematic sampling: Chọn liên tiếp các quan sát tại vị trí thứ k của tổng thể cho đến khi đạt được kích thước của mẫu như mong muốn.
-
Stratified random sampling: Từ tổng thể được chia thành các nhóm nhỏ dựa trên đặc điểm tính chất. Sau đó, các mẫu sẽ được rút ngẫu nhiên từ các nhóm theo số lượng dựa trên tỷ trọng của nhóm với tổng thể.
-
Clustered sampling: Mẫu được lựa chọn bằng cách từ tổng thể chia thành các cụm nhỏ, sau đó các quan sát sẽ được chọn ngẫu nhiên từ các cụm này.
2. Lấy mẫu phi xác suất (Non-probability Sampling)
-
Convenience sampling: Lựa chọn mẫu dựa trên tính dễ truy cập, sử dụng dữ liệu sẵn có.
-
Judgmental sampling: Lựa chọn mẫu dựa trên kinh nghiệm và nhận định của người lựa chọn.
[LOS 7.b] Giải thích định lý giới hạn trung tâm và tầm quan trọng của nó đối với phân phối và Giải thích khái niệm sai số chuẩn của trung bình mẫu
1. Sai số lấy mẫu (Sampling error)
Sai số lấy mẫu (sampling error) là sự khác biệt về số liệu thống kê (mean, variance, …) giữa mẫu và tổng thể.
Ví dụ: Sampling error of the mean = Sample mean – Population mean = X − μ
2. Định lý giới hạn trung tâm (Central limit theorem)
Đặc điểm chính
-
Nếu cỡ mẫu n đủ lớn (n ≥ 30), thì phân phối của trung bình mẫu (Sampling distribution of the sample means) sẽ xấp xỉ phân phối chuẩn.

Phát biểu định lý
Phân phối của trung bình mẫu (sampling distribution of the sample means) xấp xỉ phân phối chuẩn.
Giá trị trung bình của các phân phối của trung bình mẫu (the mean of the distribution of all possible sample means) = 𝜇 (trung bình tổng thể).
Phương sai của các phân phối của trung bình mẫu = 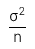
3. Sai số chuẩn của trung bình mẫu
Định nghĩa:
Sai số chuẩn của trung bình mẫu (standard error of the sample mean) là độ lệch chuẩn của các phân phối của trung bình mẫu.
Công thức:
Khi biết độ lệch chuẩn của tổng thể:
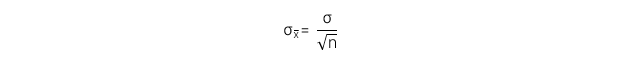
Khi không biết độ lệch chuẩn của tổng thể:
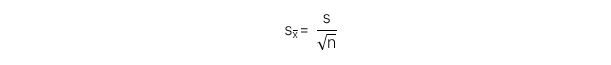
[Pre.i&ii] So sánh ước tính điểm và ước tính khoảng tin cậy của tham số tổng thể; Phân biệt ước tính điểm và ước tính khoảng tin cậy của tham số tổng thể
Khái niệm: Khoảng tin cậy (confidence interval) là một khoảng giá trị xung quanh giá trị kỳ vọng mà ta kỳ vọng xác suất nó bao hàm giá trị thực là 100(1 – α)%, với 1 – α là độ tin cậy (degree of confidence) hay α là mức ý nghĩa thống kê (level of significance).
Công thức:
Khi biết phương sai của tổng thể:

Khi không biết phương sai của tổng thể:

Tiêu chí để chọn thống kê kiểm định (test statistic) thích hợp
|
Khi lấy mẫu từ |
Test statistic |
|
|
Mẫu nhỏ (n<30) |
Mẫu lớn (n≥30) |
|
|
Tổng thể là một phân phối chuẩn đã biết phương sai |
Z - statistic |
Z - statistic |
|
Tổng thể là một phân phối chuẩn chưa biết phương sai |
T - statistic |
T - statistic |
|
Tổng thể không phải là một phân phối chuẩn đã biết phương sai |
Not available |
Z - statistic |
|
Tổng thể không phải là một phân phối chuẩn chưa biết phương sai |
Not available |
T - statistic |
[LOS 7.c] Mô tả các phương pháp tái chọn mẫu để ước tính phân phối lấy mẫu của một thống kê
Tái chọn mẫu (resampling) là một công cụ tính toán lặp lại các mẫu từ mẫu dữ liệu quan sát ban đầu để suy luận thống kê các tham số dân số.
Các phương pháp lấy mẫu phổ biến:
-
Bootstrap: Lấy mẫu bằng cách lặp đi lặp lại từ mẫu ban đầu để tìm sai số chuẩn và khoảng tin cậy.
-
Jackknife: Lấy mẫu dữ liệu quan sát ban đầu và loại bỏ một quan sát tại một thời điểm từ tập hợp (và không thay thế nó).
[Pre.iii] Mô tả các vấn đề liên quan đến việc lựa chọn cỡ mẫu thích hợp và các loại thiên lệch xung quanh việc chọn mẫu
Các vấn đề liên quan đến việc lựa chọn cỡ mẫu thích hợp, gồm có:
-
Yêu cầu độ chính xác
-
Rủi ro lấy mẫu từ một tổng thể khác
-
Chi phí của các cỡ mẫu khác nhau.
Các loại thiên lệch phổ biến:
-
Thiên lệch do khai phá dữ liệu (Data snooping bias): Xảy ra khi lặp đi lặp lại quá trình khai thác dữ liệu từ một bộ dữ liệu cho tới khi đạt được kết quả mong muốn.
-
Thiên lệch trong chọn mẫu (Selection bias): Xảy ra khi dữ liệu bị loại bỏ khỏi quá trình phân tích một cách có hệ thống, thường do không còn khả dụng.
-
Thiên lệch tồn tại (Look-ahead bias): Xảy ra khi nghiên cứu sử dụng dữ liệu chưa khả dụng tại thời điểm nghiên cứu.
-
Thiên lệch khoảng thời gian (Time period bias): Xảy ra khi dữ liệu được thu thập trong khoảng thời gian quá ngắn hoặc quá dài.